
OCR ဆိုတာကိုမေျပာခင္မွာအရင္ရွင္ျပခ်င္တာကေတာ့ကၽြန္ေတာ္တို႕
သာမာန္အားျဖင့္
E-book (PDF) ေတြမွာအမ်ိဳးအစားအားျဖင့္ ႏွစ္မ်ိဳး
ရွိပါတယ္။၄င္းတို႕ကေတာ့
Image PDF နဲ႕ Text PDF ဆိုပီးေတာ့ေပ့ါ
ဘာေတြကြာျခားသလည္းဆိုေတာ့
ကၽြန္ေတာ္တို႕ Text PDF ေတြမွာ
ဆိုရင္ေတာ့
၄င္း PDF File အတြင္းပါ၀င္ေသာ စာသားမ်ားအားအလြယ္
တကူ Ctrl
+ F (Search) လုပ္ပီးရွာေဖြလို႕ေပမယ့္။ Image PDF ေတြ
မွာကေတာ့
Search လုပ္ခြင့္မရွိပဲ PDF File တစ္ခုလံုးက Image တစ္ခု
ကို Scan
ဖတ္ထားပီး PDF Converting လုပ္ထားသလိုမ်ိဳးျဖစ္ေနေသာ
ေၾကာင့္ျဖစ္ပါတယ္။
ဒါေၾကာင့္ ကၽြန္ေတာ္တို႕က OCR Service ပါေသာ
Reader သို႕မဟုတ္၊
OCR Software တစ္မ်ိဳးမ်ိဳးျဖင့္ ၄င္း Image PDF
မ်ားကို
Text PDF အျဖစ္သို႕ ေျပာင္းလည္းရပါတယ္။ဒါေၾကာင့္ အခု
ဒီေခါင္းစဥ္ေအာက္မွာကၽြန္ေတာ္က
PDF-X Change Viewer နဲ႕
Adobe
Reader ႏွစ္ခုကိုယွဥ္ပီးေျပာသြားပါမယ္။လိုအပ္တဲ့
Software ကိုေတာ့ ဒီမွာေဒါင္းလိုက္ပါ အိုေခအရင္ဆံုး
သင့္စက္ထဲကို
PDF-X Change Viewer Software ကို Install
လုပ္လုိက္ပါ။
အားလံုးဟာပံုမွန္အတိုင္းပါပဲအဲဒီေနရာမွာတစ္ခု
ေျပာခ်င္တာက
Installation အပိုင္းေပါ့.. Select Components
ဆိုတဲ့အပိုင္းေရာက္ရင္ေအာက္ပါပံုအတိုင္း

မွ်ားအနီေလးျပထားတဲ့
OCR ဆိုတဲ့ Service ေလးကိုအမွန္ျခစ္မျဖဳတ္မိဖို႕ျဖစ္ပါတယ္။
ကဲ
Software ကုိစာဖတ္သူသြင္းပီးသြားပီလို႕ ယူဆလိုက္ပါတယ္။ဒါေၾကာင့္ ဆက္ရေအာင္
ဥပမာတစ္ခုအေနနဲ႕
ကၽြန္ေတာ္က Image PDF ဖိုင္တစ္ခုကိုဖြင့္ပီး ၄င္းထဲမွာပါ၀င္ေသာ
Word တစ္ခုခုအား
Search ျဖင့္ ရွာၾကည့္လိုက္ပါတယ္။ ပထမဦးဆံုး Adobe Reader
ထဲကေနေပ့ါ…

အထက္ပါပံုအတိုင္းသင္ရိုက္ရွာလိုက္ေသာစာသားဟာမရွိပါဘူးဆိုပီးေတာ့
Message ေဖာ္ျပပါတယ္။ေနာက္တစ္ခုX
Change Viewer အတြင္းမွာလည္း
ထပ္မံရွာၾကည့္ပါတယ္။
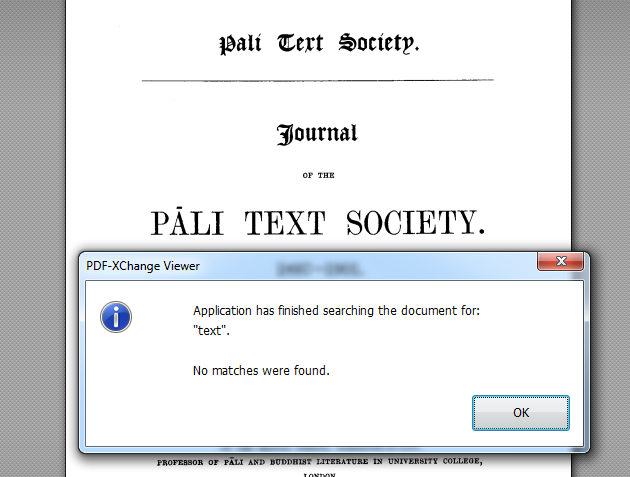{kind=link}

ဒီထဲမွာလည္းမေတြ႕ဘူးလို႕ေျပာပါတယ္။
ဒါဟာ Image PDF ဖိုင္ျဖစ္ေနလို႕ပါပဲ…
ကၽြန္ေတာ္တို႕က
Adobe Reader ထဲမွာဆိုရင္ OCR Service Mode မပါ၀င္တဲ့
အတြက္ေၾကာင့္
၄င္း Image PDF ကို Text PDF အျဖစ္ Convert လုပ္လို႕မရပါ
ဘူး။ ဒါေၾကာင့္
ကၽြန္ေတာ္တို႕က X Change Viewer ထဲကေန Convert လုပ္မွာ
ျဖစ္ပါတယ္။
ဒါေၾကာင့္ေအာက္ပါပံုအတိုင္း

မွင္အနီေရာင္ေလး၀ိုင္းျပထားတဲ့ေနရာမွာ
OCR ဆိုတာကို ႏွိပ္လိုက္ပါမယ္။
ဒီအခါမွာေတာ့
ေအာက္ပါပံုအတိုင္း

OCR
Converting Service ModeMenuေပၚလာတဲ့အခါမွာေတာ့ ဘာမွ
မေျပာင္းလည္းပဲ
OK ဆိုတာကိုႏွိပ္လိုက္ပါ့မယ္။ဒါဆိုရင္ေအာက္ပါပံုအတုိင္း

သင့္
Image PDF File အတြင္းရွိစာမ်က္ႏွာအားလံုးကို Text PDF ဖုိင္အျဖစ္
သို႕
Converting လုပ္ေနတာျဖစ္ပါတယ္။ဒီေနရာမွာစာရြက္ရည္မ်ားလွ်င္မ်ား
သလိုအခ်ိန္အားျဖင့္လည္းအနည္းငယ္
ၾကာျမင့္ပါမယ္။ဒီေနာက္ Converted
ပီးသြားတာနဲ႕
ကၽြန္ေတာ္တို႕ကခုနကရိုက္ရွာတဲ့ “text “ ဆိုတာကိုထပ္မံရိုက္ပီး
ရွာတဲ့အခါမွာေတာ့

အထက္ပါပံုအတိုင္း
PDF ဖိုင္ထဲမွာရွိသမွ် TEXT ႏွင့္ ပတ္သက္သမွ် စကားလံုး
တိုင္းကိုေဖာ္ျပေပးမွာျဖစ္ပါတယ္။ဒါဟာဘာေၾကာင့္လည္းဆိုေတာ့
လက္ရွိ
Image
PDF ကေန Text PDF အျဖစ္သို႕ OCR Services Mode ကိုအသံုးျပဳ
ပီး
Converted လုပ္လုိက္ေသာေၾကာင့္ျဖစ္သည္။ အခုေနာက္ပိုင္း Adobe
Reader ေတြဘယ္ေလာက္ပဲထြက္ထြက္
OCR Service မပါပါဘူး။ သို႕ေပ
ေသာ္ညာလည္း
Adobe Acrobat Reader မွာကေတာ့ OCR ကို Support
လုပ္တာကိုေတြ႕ရွိရပါတယ္။
ဒီေလာက္ဆိုရင္ ကၽြန္ေတာ္တို႕ဖတ္ေနၾကတ့ဲ
PDF အေၾကာင္းနဲ႕
OCR အေၾကာင္းကိုအၾကမ္းဖ်ဥ္းေလးသေဘာေပါက္
နားလည္မယ္လို႕
ယံုၾကည္ေမွ်ာ္လင့္မိပါတယ္။ ဒီ Post ေလးျဖစ္ေျမာက္ဖို႕
အႀကံဥာဏ္ရေအာင္
ကၽြန္ေတာ့္ရဲ႕ Customer တစ္ဦးျဖစ္တဲ့ ဗီယက္နမ္
တစ္ေယာက္လည္းဒီ
Post ေလးနဲ႕ ဂုဏ္ျပဳလိုက္ပါတယ္။
ေလးစားစြာျဖင့္
Cristiano
Zarni@ ဦးဇာနည္
No comments:
Post a Comment